Implement strStr().
Return the index of the first occurrence of needle in haystack, or -1 if needle is not part of haystack.
Example 1:
Input: haystack = “hello”, needle = “ll”
Output: 2
Example 2:
Input: haystack = “aaaaa”, needle = “bba”
Output: -1
蛮力法
双指针,i遍历主串,j遍历模式串,当s[i] != p[j]时,回溯,i回溯到i - j + 1的位置,j = 0;
如图,当i = 10,j = 6时,字符不匹配。
令i = 5, j = 0,
如图
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public int strStr(String s, String p) {
int n = s.length(), m = p.length();
int i = 0, j = 0;
while (i < n && j < m) {
if (s.charAt(i) == p.charAt(j)) {
i++;
j++;
} else {
i = i - j + 1;
j = 0;
}
}
if (j == len2) return i-j;
else return -1;
}
蛮力法的时间复杂度是O(nm)。
KMP算法
在蛮力法中,当s[i] != p[j]时,i回溯到了i - j + 1的位置,入上图,当s[10] != p[6]时,i重新向前移动到了5,实际上,在i >= 5和i <=10 之间,我们已经与模式串p比较过了,如果在字符串开始查找的时候,能够构造一个表,使得当字符匹配失败时,利用主串与子串已经匹配过得字符,让i不再回溯而是仍然保持着当前匹配失败的时候的值,j也尽可能从大于0的位置开始与主串中的字符进行比较,就能减少字符的比较次数。在KMP算法中,我们可以构造一个next数组,当s[i] != p[j]即匹配失败时,直接令j = next[j]而不是向蛮力法一样回溯到0,如下图, 。
。
算法使得i位置保持不变,j = 2,直接让s[10]与p[2]进行比较。抽象一下,如图所示, 当匹配失败时,字符串向右滑动了j - next[j]位。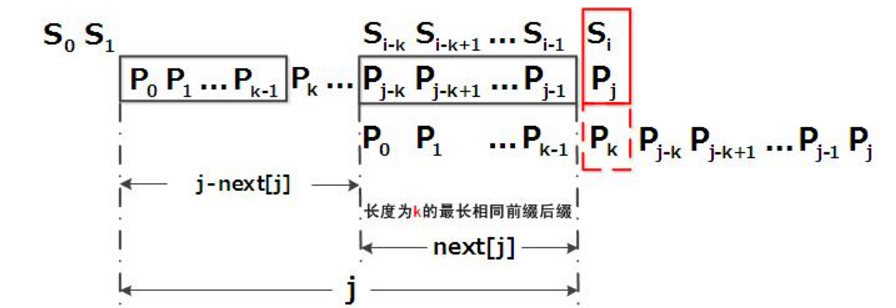 ,此时p[0 ~ k-1] == p[j-k ~ j-1]
,此时p[0 ~ k-1] == p[j-k ~ j-1]
next[j]如何确定?
我们令k = next[j],next[j]为p[0]与p[j -1]之间的子串的前后缀的公共元素的最大值。所谓字符串的前缀,就是一定包含第一个元素和一定不包含最有一个元素的子串,字符串的后缀就是一定包含最后一个元素和一定不包含第一个元素的子串。如图展示了字符串”ababa”的前缀与后缀以及公共元素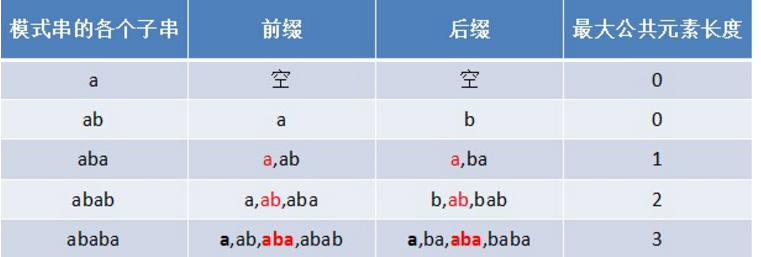
用代码求next数组
已知next [0, …, j],如何求出next [j + 1]呢?
对于P的前j+1个序列字符:
若p[k] == p[j],则next[j + 1 ] = next [j] + 1 = k + 1;
若p[k ] ≠ p[j],如果此时p[ next[k] ] == p[j ],则next[ j + 1 ] = next[k] + 1,否则继续递归前缀索引k = next[k],而后重复此过程。 相当于在字符p[j+1]之前不存在长度为k+1的前缀”p0 p1, …, pk-1 pk”跟后缀“pj-k pj-k+1, …, pj-1 pj”相等,那么是否可能存在另一个值t+1 < k+1,使得长度更小的前缀 “p0 p1, …, pt-1 pt” 等于长度更小的后缀 “pj-t pj-t+1, …, pj-1 pj” 呢?如果存在,那么这个t+1 便是next[ j+1]的值,此相当于利用已经求得的next 数组(next [0, …, k, …, j])进行P串前缀跟P串后缀的匹配。
